FEATURED STORY OF THE WEEK
Beyond Raw Power: How Smart Inference Strategy Reduces AI Infrastructure Costs Without Sacrificing Performance

Introduction: AI’s Quiet Cost Crisis
Everyone talks about training AI. But the moment your LLM goes live, inference becomes the silent budget killer.
If you’re scaling GenAI, copilots, or chatbots, you’re not asking, “Can we build it?” You’re asking, “Can we afford to run it?” The stakes are high—performance, user experience, and cost are all locked in a constant tug of war. This guide is your blueprint for navigating that tension—and winning.
Whether you’re deploying NVIDIA H100 Tensor Core GPUs today or exploring a future built on the NVIDIA H200 and Blackwell architecture, this post will help you:
- Cut inference costs at scale
- Maximize throughput without tanking UX
- Deploy smarter, faster, and more efficiently

1. Why Inference Is Where the Real Costs Are
Once you deploy an LLM or multimodal model, the real game begins: serving that model efficiently, repeatedly, and at scale.
Inference eats into:
- Operational expenses (every token served has a cost)
- User experience (latency = churn)
- Data center energy budgets (especially with GPU sprawl)
It’s no surprise that enterprises are shifting focus to inference-first architecture planning. Your infrastructure must be fine-tuned—not just powerful.
2. Key Metrics That Actually Matter
Let’s cut through the noise. These are the numbers you’ll want to tattoo onto your Ops dashboards:
- Cost Per Token (CPT): If you’re not measuring this, you’re already overpaying.
- TTFT + TPOT: Time to First Token and Time Per Output Token aren’t vanity metrics—they’re business SLAs.
- Goodput: Peak throughput that still meets your latency targets. That’s the holy grail.
- Time to Market: Inferencing stacks that require weeks to integrate? You’ll bleed opportunity cost.
Your performance model must balance scale, latency, and budget. All three. Every day.
3. What Use Case-Driven Hardware Planning Looks Like
Benchmarks don’t win in production. Use cases do.
- Chatbots need lightning-fast TTFT and acceptable TPOT. Speed = user trust.
- Summarization can tolerate slower starts but must output full summaries quickly.
- RAG workflows depend on fast interconnects and high memory bandwidth.
- AI Agents? They demand orchestration stacks, not standalone servers.
Pro tip: Don’t just benchmark “throughput.” Benchmark “throughput while meeting UX standards.”
4. Architecting Inference: From GPU Choice to Batching Strategy
When it comes to inference, architecture is destiny.
- The Hardware Shortlist
- NVIDIA H100 Tensor Core GPUs: Enterprise staple for 2024, with powerful support for LLM workloads.
- NVIDIA H200 GPUs: Next-gen Blackwell architecture with FP4 precision and up to 30x faster inference for trillion-parameter models.
- Grace Blackwell GB200: One chip, two Blackwells, one Grace CPU—delivers 900 GB/s bandwidth with 1/5th the energy draw.
- The Rack That Replaces a Cluster
- NVL72: 72 H200-class GPUs working as one liquid-cooled mega-GPU. Massive models. Tiny energy bills. It’s an ops dream.
- The Batching Playbook
- Dynamic batching: Group incoming requests based on size or delay.
- Inflight batching: Never wait. Always process.
- Sequence batching: Ideal for things like video or multimodal pipelines.
- Model concurrency: Run multiple models on a single GPU using Triton Inference Server.
This is how you move from “just running” to “running smart.”
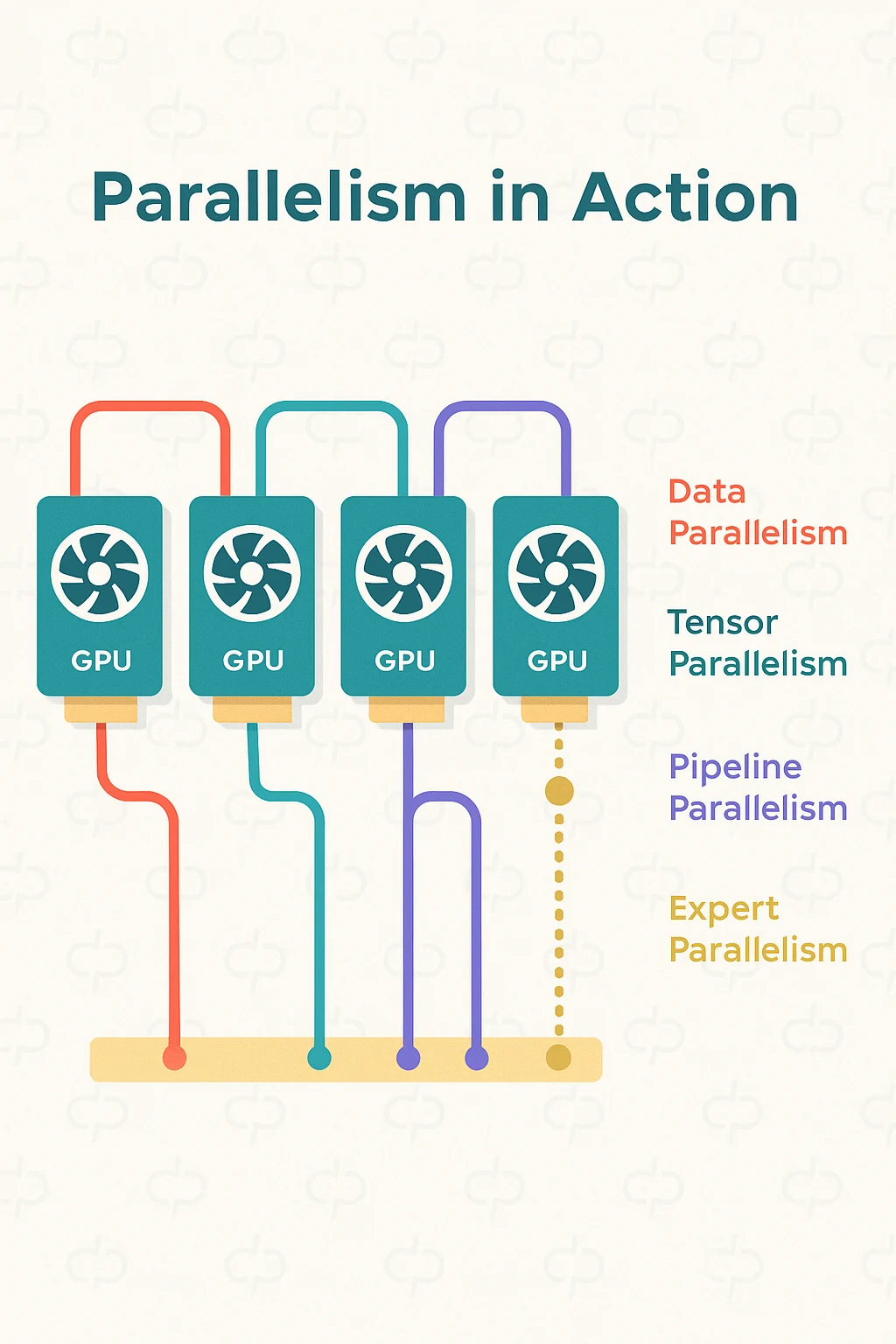
5. Parallelization Techniques for Giant Models
Your model doesn’t fit on one GPU anymore? No problem. Just parallelize—intelligently.
- Data Parallelism (DP): Clone the model, spread requests.
- Tensor Parallelism (TP): Slice model weights. Requires low-latency interconnects.
- Pipeline Parallelism (PP): Divide by layers. Effective but adds latency.
- Expert Parallelism (EP): Route to “experts.” Reduces overhead.
Best in class? Use combinations like EP16PP4—expert + pipeline. It doubles interactivity without sacrificing throughput.
6. Smarter Cloud Scaling Without Lock-In
Inference scales fast. But cloud costs? They scale faster.
Here’s the playbook:
- Use accelerated compute instances (e.g., AWS, Azure, GCP with NVIDIA GPUs)
- Avoid vendor lock-in by standardizing on cross-cloud inference stacks
- Deploy Kubernetes + NVIDIA Triton/NIM for dynamic scaling based on queue length
- Integrate with MLOps tools: MLflow, Prometheus, HPA
Forecasting is hard. Scaling smart is harder. This makes it manageable.

7. Advanced Techniques for Inference Pros
If you’re running AI at scale—or AI is part of your product—these are non-negotiables:
- Chunked Prefill: Split LLM prefill into parallelizable chunks.
- Multiblock Attention: Better decoding for long contexts (think Llama 3.1 128K tokens).
- KV Cache Early Reuse: Recycle as you go. Save time and tokens.
- Disaggregated Serving: Decouple prefill and decode stages. Lower infra costs by 50%.
- Speculative Decoding: Guess smart. Predict multiple tokens in parallel. 3.5x throughput gains.
These aren’t lab tricks. These are production-grade tools used by top AI companies right now.
8. Real-World Wins: Wealthsimple, Amdocs, Perplexity, and Let’s Enhance
Wealthsimple
→ Cut model delivery time from months to 15 minutes
→ 145M predictions with zero IT tickets
→ 99.999% inference uptime using NVIDIA Triton
Perplexity AI
→ Handles 435M+ queries/month with NVIDIA H100 + TensorRT-LLM
→ Schedules 20+ models, meets strict SLAs, slashes CPT
Amdocs (amAIz)
→ 80% latency reduction, 30% accuracy gain, 40% token savings
→ Powered by NIM microservices on DGX Cloud
Let’s Enhance
→ Migrated SDXL to NVIDIA L4s on GCP
→ 30% cost savings, using Triton + dynamic batching
These aren’t theoretical. These are today’s results from teams optimizing with NVIDIA H100 and moving toward NVIDIA H200.
9. Final Takeaways for IT Leaders
Here’s your cheat sheet:
Benchmark the right things: CPT, Goodput, TTFT, TPOT
Match architecture to use case—not just to budget
Use NVIDIA’s ecosystem: Triton, TensorRT, NIM, H100, and H200
Scale smart in the cloud. Avoid vendor traps.
Don’t ignore batching, ensembles, or parallelism.
Deploy advanced inference techniques before your infra breaks
Let your use case dictate your roadmap—not the hype cycle
Want to dive deeper? Breakout posts on dynamic batching, NVIDIA H200 vs H100 comparison, and cloud autoscaling with Kubernetes are coming next.
Or talk to our experts at Contact Semifly – Get in Touch for Technology Services
Would you like this packaged into an SEO-ready HTML export, or broken into a content cluster?



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now