FEATURED STORY OF THE WEEK
H100 vs H200 Specs : Synthetic vs Real-World Benchmarks in GPU Testing

The H100 vs H200 debate isn’t about raw specs—it’s about whether your infrastructure is ready for real-world AI at scale. Here’s how to pick the right GPU, test it right, and future-proof your stack.
1. You Can’t Manage What You Can’t Measure
You’re trying to future-proof your AI infrastructure, right?
Great. Then benchmarking isn’t optional—it’s survival.
But here’s the twist: not all benchmarks are built the same.
You’ve got two types battling it out: synthetic benchmarks — the pristine lab coat tests that show peak performance,
and real-world benchmarks — the messy, boots-on-the-ground trials that simulate what your team actually deals with at 2 AM when latency spikes and your chatbot starts hallucinating product SKUs.
So when you’re comparing NVIDIA’s H100 vs H200 Specs, it’s not just about who wins on paper. It’s about who holds up when your pipeline’s full, the batch size doubles, and there’s no margin for “almost enough.”
2. H100 vs H200 Specs Aren’t Just Specs—They’re Strategic Signals
You’ve seen the datasheets, but let’s decode what they actually mean for you.
Memory: The AI Bouncer
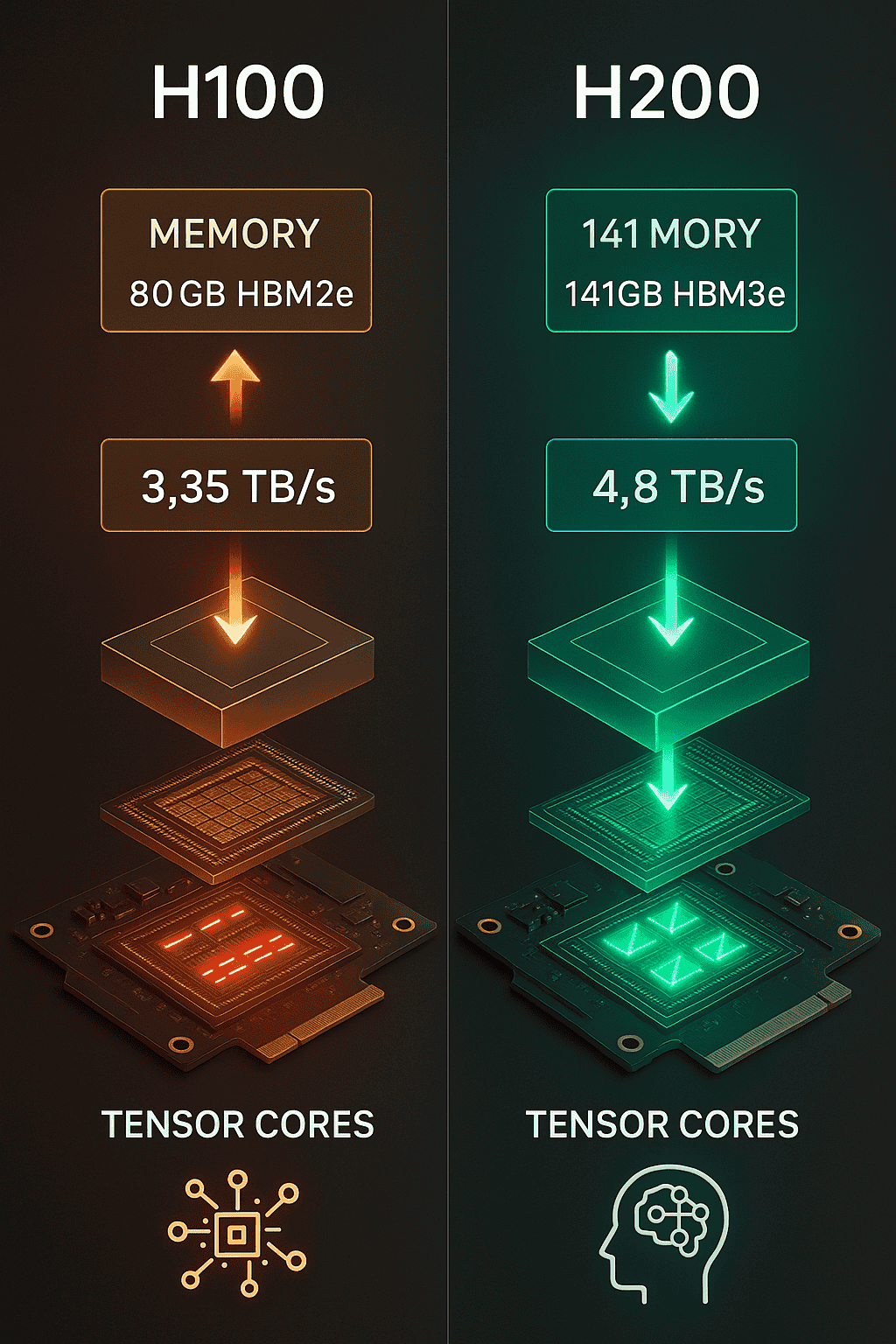
- H100: 80GB HBM2e
- H200: 141GB HBM3e
That’s not just an upgrade—it’s a redefinition of what fits inside a single GPU. With 141GB, the H200 can keep trillion-parameter models in one memory space. No splitting. No latency tradeoffs. Just throughput.
In production? That means you’re not juggling data across multiple GPUs or worrying about out-of-memory errors mid-training. Think fewer interruptions, more continuity.
Bandwidth: Your Data Highway
- H100: 3.35 TB/s
- H200: 4.8 TB/s
Imagine moving semis vs. fighter jets on a runway. That’s what 4.8 TB/s gets you—more data, faster, with fewer stalls when your LLM inference pipeline is under fire.
Tensor Cores: The AI Engines
Both have 4th-gen Tensor Cores. But the H200’s been fine-tuned for inference. It’s like tuning the same car for the racetrack instead of off-roading—same engine family, different specialization.
In real-world use, that means lower latency per token, especially when decoding long sequences. That’s a big deal for customer-facing use cases like personalized virtual assistants.
Synthetic Benchmarks: The Lab Tests
Coming to H100 vs H200 Specs. Think of synthetic benchmarks as a “track day” for your GPU. They’re controlled. Repeatable. But no potholes, no traffic, no rain.
The Good Stuff
- MLPerf: The gold standard.
- Scenario: Run GPT-3 size models and compare throughput.
- Result: H200 offers ~2x the throughput of H100 in LLM inference.
Use case? You’re building an internal model evaluation framework. MLPerf scores help you vet contenders before you build expensive environments around them.
When to Use Them
- Need to compare GPUs head-to-head without software noise.
- Evaluating hardware upgrades in a vacuum (R&D labs, academic settings).
But the Catch?
No flaky drivers. No multi-tenant jitter. No network backpressure. It’s like testing a Formula 1 car in a wind tunnel and assuming it’ll dominate LA traffic.
Also? They don’t reflect tuning headaches. PyTorch might behave differently than TensorFlow. Those quirks matter—just ask any engineer who’s had to rewrite ops for CUDA compatibility.
Real-World Benchmarks: Messy, But Meaningful
When it comes to H100 vs H200 Specs. You wouldn’t deploy a car without road-testing it, right? Same here.
Real-world benchmarks show how H100 or H200 performs in your environment, with your data, under your conditions.
Example: TensorRT-LLM for Inference
- Batch Sizes: H200 eats bigger batches without flinching.
- Latency: Down. Way down.
- Energy Use: H200 runs cooler and cheaper per inference.
Consider a healthcare deployment. You’re running diagnostic inference on medical images and notes. The H200’s ability to batch process with minimal lag can mean faster patient outcomes, without ballooning your data center bill.
Real-World Wins
- Mirrors your deployment setup (drivers, frameworks, interruptions).
- Tracks TCO better—especially on energy and latency.
Real-World Risks
- Hard to replicate across orgs.
- Can become anecdotal if not standardized.
You need careful documentation, plus simulation runs that mirror traffic peaks and memory-bound inference chains. But when done right? It tells you whether your stack can handle real demand—not just slideware projections.
5. Side-by-Side: Where H100 Still Makes Sense
Here’s your quick side-by-side:
| Feature | H100 | H200 |
|---|---|---|
| Memory | 80GB HBM2e | 141GB HBM3e |
| Bandwidth | 3.35 TB/s | 4.8 TB/s |
| FP8 Performance | 3,958 TFLOPS | 4,537 TFLOPS |
| Ideal Use Case | Compute-heavy | Memory-heavy |
| LLM Inference | Moderate batch | High batch |
| GenAI Workloads | Sufficient | Optimized |
| Power Efficiency | Good | Better |
| Real-Time Scalability | Mid-tier | Enterprise-grade |
Use H100 when:
- You’re dealing with legacy models or regional deployments.
- You’re running classic HPC apps (e.g., seismic analysis, molecular dynamics).
- Your IT budget demands ROI within a 12-month payback cycle.
Other than what is mentioned in H100 vs H200 Specs sheet. The H200 wins on capacity and headroom. But the H100 holds the line where compute per dollar still rules.
6. Benchmarking Strategy: Know What You’re Measuring
Here’s the million-dollar question: What are you optimizing for?
If you’re in AI R&D…
- Prioritize synthetic benchmarks.
- You’re stress-testing hardware limits. Think trillions of parameters. You need headroom, and the H200 gives you that.
If you’re in enterprise IT…
- Prioritize real-world benchmarks.
- You care about uptime, latency, TCO, and energy. That’s where the H200’s efficiency and large-batch handling truly shine.
Mix Both When…
- You’re moving from experimentation to production.
- Start synthetic → validate with real-world → scale.
Add an internal checkpoint: Build a benchmarking dashboard that tracks memory usage, response time, and cost-per-token. That turns benchmarking into a continuous loop—not a one-and-done metric.
7. Why This Matters Beyond the Numbers
Look, H100 vs H200 specs don’t win business cases. Outcomes do.
Decision-Making Scenarios
- Startup CTO: Pitching VCs? Benchmark your H200 pipeline across video, vision, and language modalities. Nothing beats multi-modal throughput in a slide deck.
- Retail CIO: Simulate Black Friday. Your chatbot and personalization engines need real-world inference data. Use NVIDIA H200 to cut latency per query while reducing GPU sprawl.
- Gov Lab Director: Classified NLP? You need lab-proofed synthetic metrics and field-ready real-world inference tuning. Especially when procurement cycles run 3–5 years.
The GPU is just one piece. The rest? It’s how you wield it.
Final Take: when it comes to H100 vs H200 specs, Benchmarks Are the Compass, Not the Map
If you remember one thing, let it be this:
The NVIDIA H200 isn’t just an upgrade. It’s a paradigm shift.
Its 141GB of HBM3e isn’t just a stat—it’s an unlock for trillion-parameter LLMs, denser models, and energy-optimized AI at scale.
But if you don’t test it right—if you rely only on lab scores without contextual trials—you’re steering blind.
So benchmark smart:
- Use synthetic benchmarks to identify hardware potential.
- Use real-world benchmarks to confirm that potential translates into impact.
Because specs are promises. Benchmarks are proof.
And you? You’re building the future. Just make sure it works under real load.
Talk to us for some realworld insights – www.semifly.ai



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now