

Emerging Cybersecurity Best Practices in Higher Education
Cybersecurity is a critical issue for universities and other institutions of higher education. These institutions already are high-value targets for cyberattacks. Now, as colleges and…
•

In AI infrastructure, raw compute often gets the headlines — FLOPs, core counts, and tensor throughput. But for real-world workloads, especially large language models (LLMs) and generative AI, memory bandwidth decides whether your cluster cruises or crawls.
The NVIDIA H200 raises the stakes with a 4.8 terabytes per second (TB/s) memory bandwidth powered by next-generation HBM3e. This isn’t just a spec sheet brag — it’s a redesign of how models can be fed data fast enough to keep 141 GB of high-bandwidth memory and Tensor Cores saturated.
For enterprises deploying AI at scale, understanding how to leverage H200 GPU memory bandwidth is the difference between underutilized silicon and production-grade throughput.
HBM3e: The Physical Backbone
The H200’s memory subsystem is built on 141 GB of HBM3e, offering a 76% increase in capacity over H100’s HBM3 and a substantial jump in peak throughput. HBM3e achieves this by:
This means your training and inference pipelines can process larger batches and longer sequence lengths without offloading to slower DDR or PCIe-attached memory.
Feeding the Tensor Cores Without Stalls
The 4.8 TB/s bandwidth ensures continuous data delivery to the Hopper architecture’s FP8/FP16/BF16 Tensor Cores. Without this throughput, tensor operations stall, wasting clock cycles and inflating time-to-convergence.
For example:
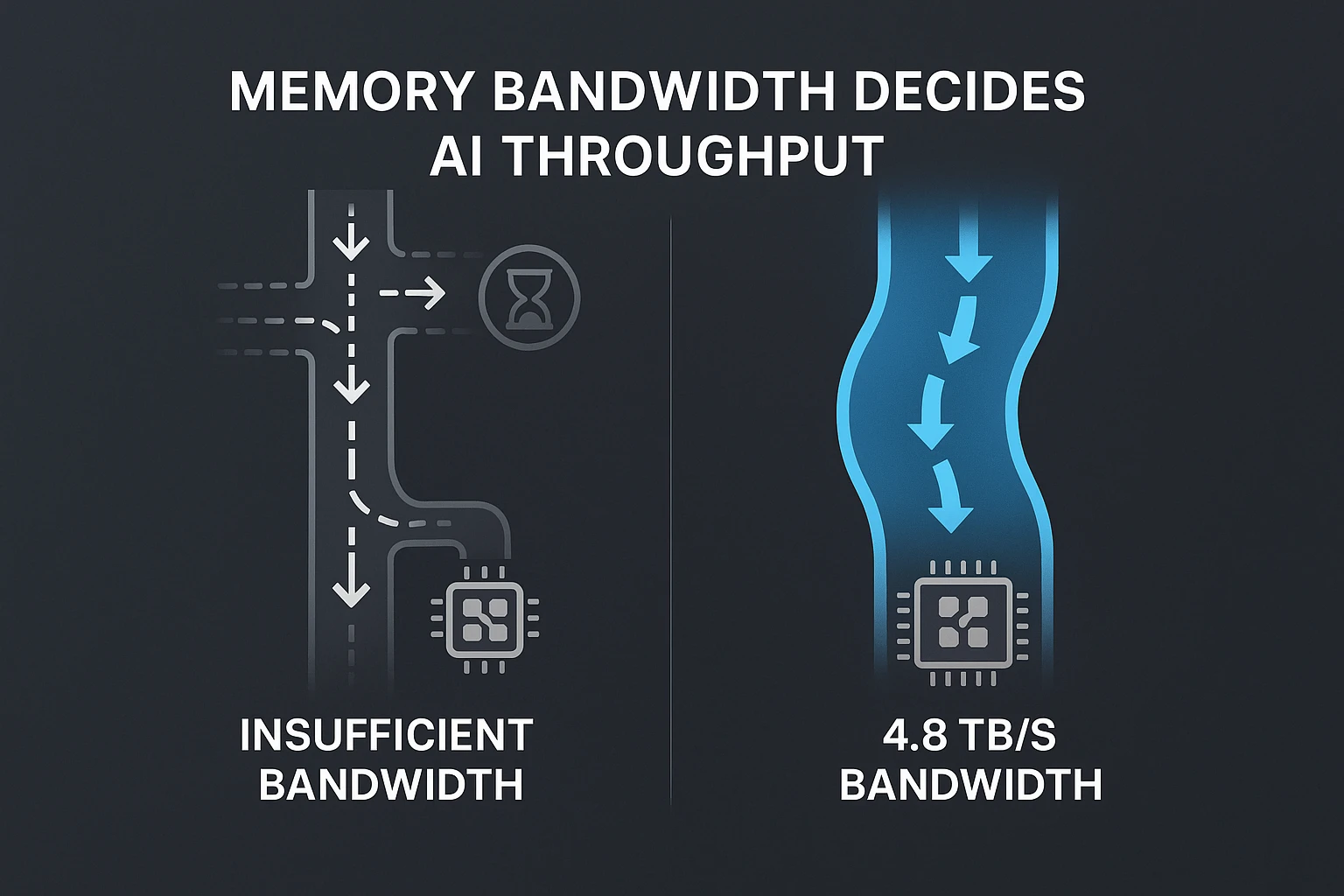
Semifly helps enterprises build H200-optimized pipelines that actually exploit this bandwidth ceiling. Without the right architecture, real-world throughput may land far below spec.
Key Design Principles:
Even with H200’s bandwidth, poorly tuned stacks lose performance to:
This is why Semifly’s pre-flight validation includes I/O flooding tests — simulating simultaneous NVLink, PCIe, and NIC loads to ensure no choke points remain before launch.

From Semifly’s recent deployments:
| Component | Semifly’s Offering |
|---|---|
| AI Hardware | NVIDIA H200 (PCIe or SXM), DGX/HGX systems |
| Isolation | MIG slicing, confidential compute (TEE) |
| Custom Orchestration | Terraform, Kubernetes, Slurm for secure AI deployment |
| Compliance Templates | Aligned with GDPR, HIPAA, EU AI Act, IndiaDP, and others |
| Model Compatibility | Hugging Face, Mistral, LLaMa2, BLOOM, regional LLMs |
The takeaway: H200’s 4.8 TB/s isn’t just theoretical — it directly compresses training timelines and inference latency when harnessed correctly.
When we design for H200 GPU memory bandwidth, we don’t stop at hardware specs. We:
This means your investment in H200 delivers peak real-world throughput from day one.
In AI compute, teraflops set the potential, but terabytes per second decide the outcome. The NVIDIA H200’s 4.8 TB/s GPU memory bandwidth is a leap forward, but only if your architecture, data pipeline, and orchestration stack are ready to exploit it.
With Semifly’s architecture-first approach, your H200 deployment won’t just have the spec — it will have the speed, efficiency, and resilience to keep up with the AI workloads of 2025 and beyond.




We are writing frequenly. Don’t miss that.

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now