FEATURED STORY OF THE WEEK
NVIDIA H200 Tensor Core GPU: The Definitive Pillar for Enterprise AI and HPC Workloads

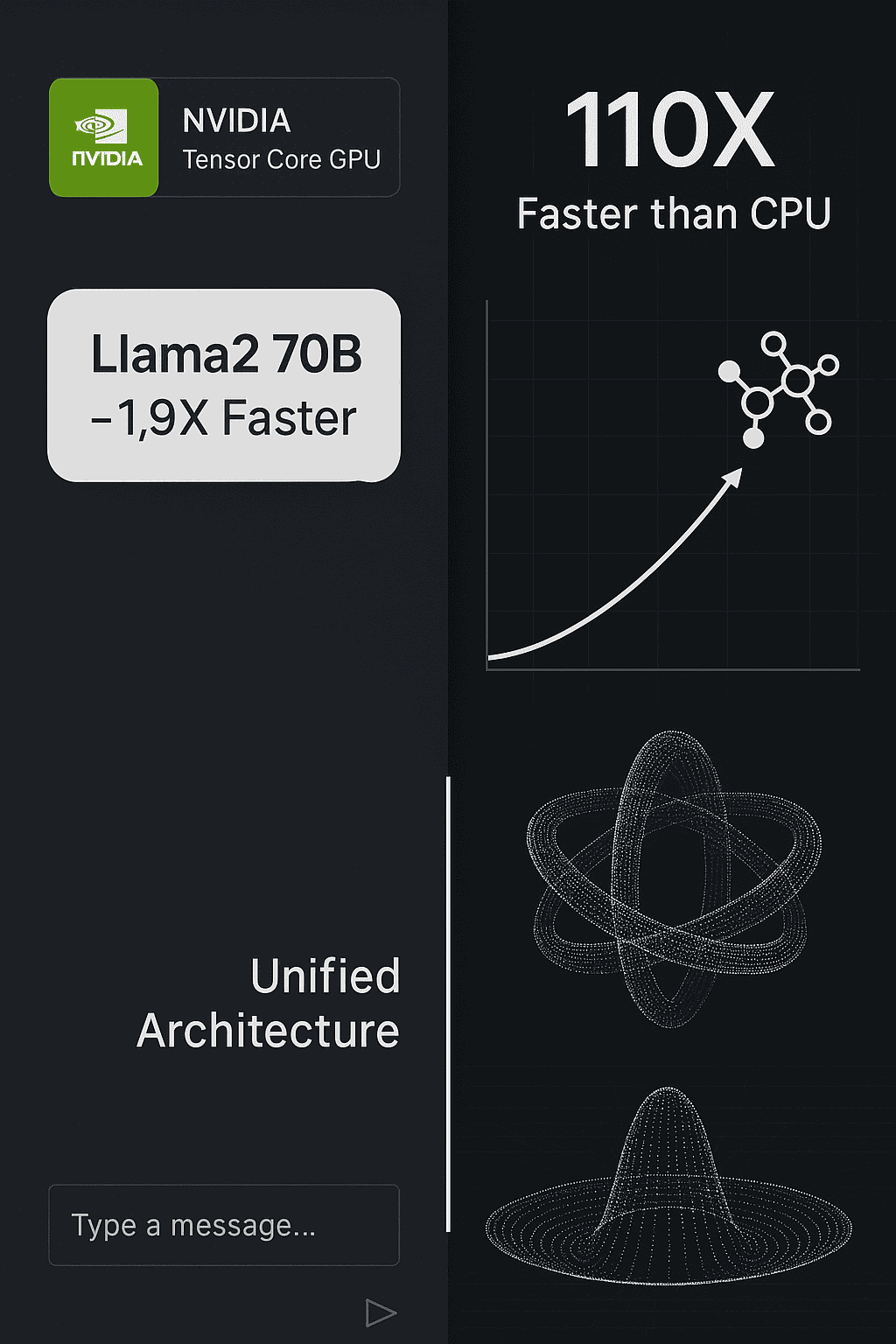
The NVIDIA H200 Tensor Core GPU is not just another incremental upgrade—it is a transformative leap forward in AI infrastructure. As the first GPU to feature HBM3e memory, the H200 brings unprecedented memory capacity and bandwidth to bear on the most demanding enterprise workloads. With up to 2X faster LLM inference performance, up to 110X faster HPC compute time compared to CPUs, and sustained power efficiency within the same thermal envelope as the H100, the H200 represents a foundational shift in how enterprises build and scale AI.
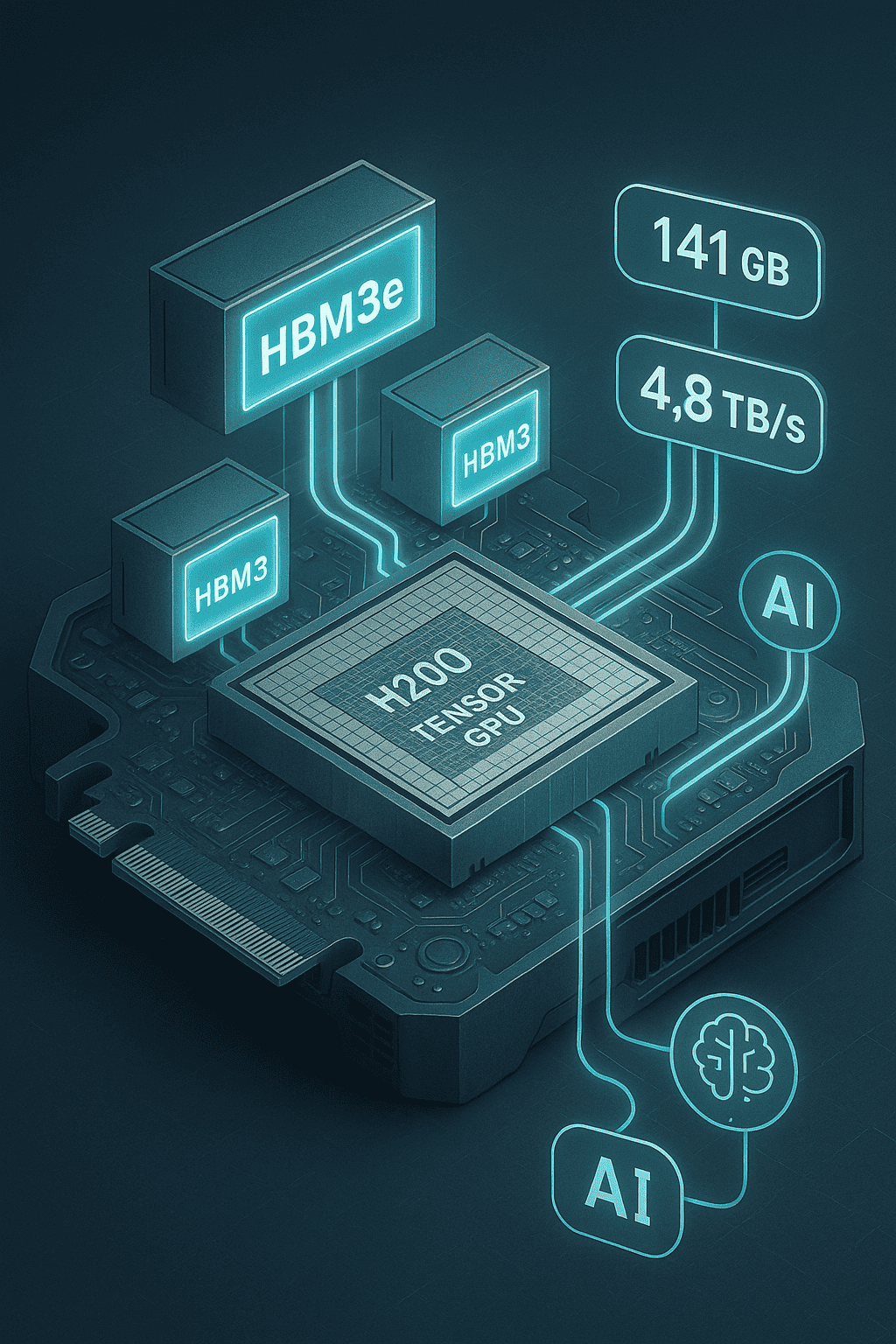
1. First GPU with HBM3e: A Memory Breakthrough
1.1 HBM3e as a Competitive Differentiator
As the first GPU with HBM3e, the H200 offers 141 GB of high-bandwidth memory at 4.8 TB/s—almost double the capacity of the H100 and with 1.4X more bandwidth. This makes it a performance enabler across both generative AI and memory-intensive scientific computing. The combination of larger capacity and higher throughput significantly accelerates auto-regressive decoding for LLMs and enables efficient single-node execution for models previously limited to distributed compute.
1.2 Unlocking Memory-Bound Performance
The H200’s memory improvements drive performance gains in areas previously bottlenecked by bandwidth constraints—such as transformer decoding, quantum simulations, and molecular dynamics.
2. Generative AI vs. HPC: Dual-Track Acceleration
2.1 Tailored for AI Inference at Scale
Benchmarks show the H200 delivering:
- 1.9X faster inference for Llama2 70B
- 1.6X faster inference for GPT-3 175B
Enterprises deploying real-time chatbots, virtual agents, and RAG pipelines can dramatically lower latency and cost-per-token with the NVIDIA H200 Tensor Core GPU.
2.2 High-Performance Computing: Time-to-Results Matters
For memory-intensive HPC applications, the H200 delivers up to 110X faster time to results compared to CPUs. From MILC and GROMACS to CP2K and Quantum Espresso, it offers domain scientists the power to iterate faster without scaling complexity.
3. Benchmarks and Validation (2025)
3.1 DeepSeek V3: Scaling Up Model Sizes
The H200 supports single-node inference for models like Llama 405B in BFLOAT16—something not feasible on GPUs with smaller memory footprints.
3.2 MLPerf Inference V5.0
The H200 ranks as a top performer across the 2025 MLPerf suite, achieving:
- 1.6X improvement over H100 on Llama2 70B
- Full compliance with new tests like Llama 3.1 405B and graph neural networks
4. Enterprise Efficiency and Sustainability
4.1 Same Power, More Output
Despite its improved performance, the H200 maintains the same TDP as the H100—700W for SXM and 600W for NVL. That means more performance per watt and less cooling infrastructure required.
4.2 50% Lower Energy Use for LLMs
NVIDIA data shows the H200 reduces energy use and TCO for LLM inference workloads by up to 50%, making it ideal for sustainable AI factories.
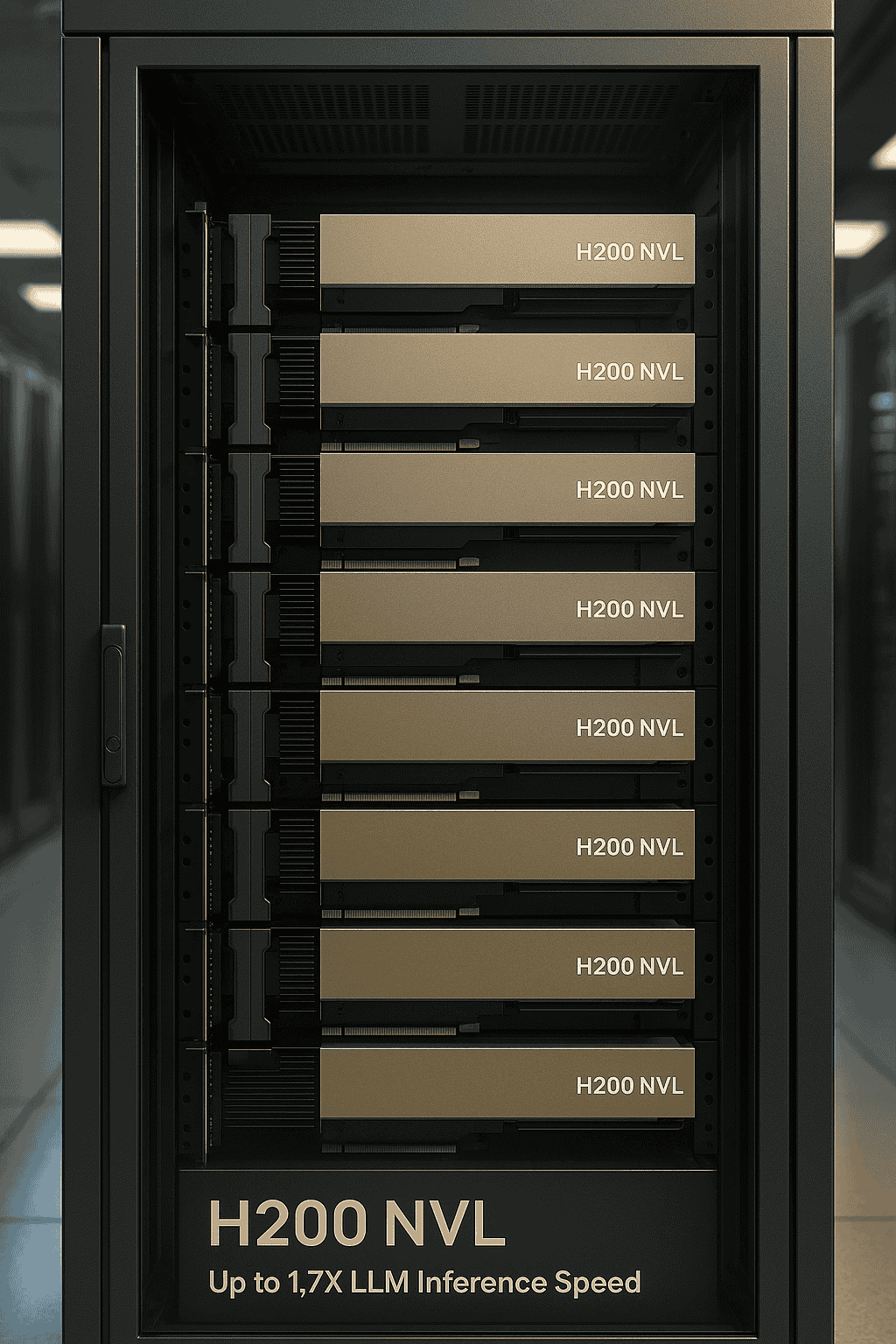
5. NVIDIA H200 NVL: Scalable Inference, Simplified
5.1 Built for Air-Cooled Enterprise Racks
The NVL form factor is designed for PCIe dual-slot air-cooled environments, supporting:
- 2-/4-way NVLink bridge at 900GB/s per GPU
- Integrated NVIDIA AI Enterprise (5-year subscription)
5.2 Real-World Performance
Compared to the H100 NVL:
- LLM inference is up to 1.7X faster
- HPC performance improves by up to 1.3X
6. Operationalizing AI with NVIDIA AI Enterprise and NIM™
6.1 API-Ready Microservices
NVIDIA NIM™ brings prebuilt containers and API-based access to models in vision, speech, and retrieval-augmented generation (RAG).
6.2 Secure, Scalable Deployments
With support for confidential computing, enterprise-grade lifecycle management, and stability guarantees, the H200 NVL is production-ready out of the box.
7. Technical Specifications: H100 vs H200 vs H200 NVL
| Feature | H100 SXM | H200 SXM | H200 NVL |
|---|---|---|---|
| FP64 | — | 34 TFLOPS | 30 TFLOPS |
| FP64 Tensor Core | — | 67 TFLOPS | 60 TFLOPS |
| FP32 | — | 67 TFLOPS | 60 TFLOPS |
| TF32 Tensor Core | 989 TFLOPS | 989 TFLOPS | 835 TFLOPS |
| BFLOAT16 Tensor Core | 989.5 TFLOPS | 1,979 TFLOPS | 1,671 TFLOPS |
| FP16 Tensor Core | 989.5 TFLOPS | 1,979 TFLOPS | 1,671 TFLOPS |
| FP8 Tensor Core | 1,979 TFLOPS | 3,958 TFLOPS | 3,341 TFLOPS |
| INT8 Tensor Core | 1,979 TFLOPS | 3,958 TFLOPS | 3,341 TFLOPS |
| GPU Memory | 80 GB | 141 GB | 141 GB |
| Memory Bandwidth | 3.35 TB/s | 4.8 TB/s | 4.8 TB/s |
| MIGs | Up to 7 @16GB | Up to 7 @18GB | Up to 7 @16.5GB |
| Decoders | 7 NVDEC, 7 JPEG | 7 NVDEC, 7 JPEG | 7 NVDEC, 7 JPEG |
| Form Factor | SXM | SXM | PCIe (air) |
| Interconnect | NVLink | NVLink/PCIe | 2-/4-way NVLink |
| TDP | 700W | 700W | 600W |
| Confidential Computing | — | Supported | Supported |
| AI Enterprise | Add-on | Included | Included |
| Server Options | HGX (4–8 GPUs) | HGX (4–8 GPUs) | MGX (up to 8 GPUs) |
Ecosystem and Deployment Readiness
8.1 Global Availability
The H200 is available through leading OEMs and CSPs, including Dell Technologies, Cisco, HPE, Lenovo, Google Cloud, and Supermicro.
8.2 Built for Cloud, Edge, and On-Prem
The platform supports deployment flexibility across multi-cloud, hybrid, and edge environments—enabling faster ROI and lower integration overhead.
Conclusion
The NVIDIA H200 Tensor Core GPU is more than a chip—it’s an infrastructure standard for AI. With HBM3e, scalable performance, and integrated enterprise software, it delivers on the trifecta of performance, efficiency, and flexibility. For CIOs, IT architects, and AI infrastructure leaders, the H200 marks a new era in accelerated computing.


More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now