

Platform Security Enhancements in Azure: 2026 Update
In the past year, Microsoft has made security its top engineering priority, committing to a company-wide Secure Future Initiative (SFI) and aligning product teams around…
•

Breaking Down the Cost of an AI-Ready Data Center
Primary Keyword: AI server data center cost
Organizations deploying AI infrastructure often discover that GPU servers account for only 60% of their total investment. The hidden costs are advanced cooling systems, power upgrades, specialized networking, and operational overhead, which can double or triple your initial budget projections.
If you’re planning an AI deployment and your calculations focus primarily on hardware acquisition costs, you’re heading toward a financial shock. This comprehensive guide exposes the true economics of AI-ready data centers, providing actionable AI server data center cost and proven optimization strategies that can save your organization hundreds of thousands of dollars.
What you’ll learn:
The shift from CPU-intensive to GPU-intensive computing has disrupted conventional data center design. AI servers, such as the HPE XD685 and Dell XE9680, equipped with eight NVIDIA H100 or H200 GPUs, consume over 7 kW per node, surpassing the 200–400 W baseline of traditional servers. This seismic shift in power demand transforms the economics of AI infrastructure.
The cost of an AI server data center now hinges on far more than just hardware. High-bandwidth interconnects, ultra-low-latency networking, dense storage, and advanced cooling skyrocket both CapEx and OpEx. These upgrades can double or triple per-rack costs, but the payoff delivers faster model training, real-time inference, and dramatically improved efficiency at scale.
Rack Density Impacts
Traditional data centers typically house 20 or more 2U servers per rack, but AI-ready facilities face a fundamentally different reality. High-performance AI nodes in 5U configurations mean that only 8-9 servers fit per rack, demolishing space utilization calculations and significantly increasing overall AI server data center costs. More critically, each H100 or H200 node consumes 5-7 kW, pushing total rack power to 50-65 kW, levels that overwhelm traditional power delivery and cooling systems.
This density challenge cascades through every aspect of infrastructure design. UPS systems must handle higher peak loads, power distribution units (PDUs) require higher current ratings, and containment strategies become essential for managing airflow. The vertical space previously used for cable management now competes with cooling infrastructure, forcing architects to rethink fundamental design assumptions.
Cooling Evolution
Traditional air cooling hits a brick wall at approximately 20kW per rack, crippling AI server data center cost projections. Beyond this threshold, the physics of heat transfer demands more sophisticated approaches. Understanding cooling options and their associated costs is crucial for accurate AI data center budgeting:. .
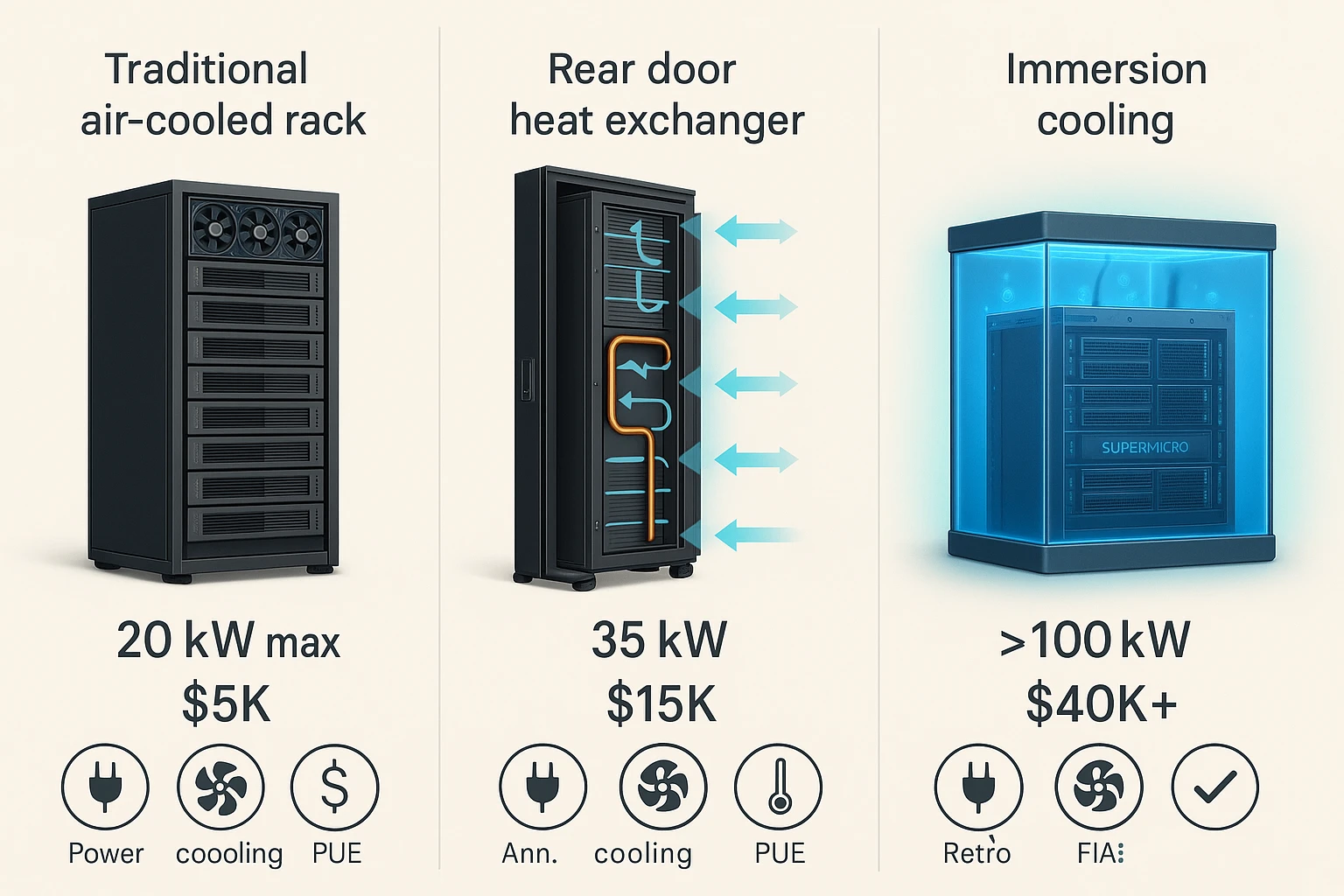
| Cooling Type | Cost per Rack | Max Rack Power | PUE Impact | Retrofit Feasibility | Key Considerations |
|---|---|---|---|---|---|
| Traditional Air | $2K–$5K | <20kW | 1.4–1.5 | Easy | Easiest retrofit path, viable for lower-density deployments |
| Rear Door Heat | $8K–$15K | ~30–35kW | 1.3 | Medium | Extends air cooling capabilities with improved efficiency |
| Liquid (Direct) | $15K–$40K | 50–70kW | 1.1–1.2 | Hard | Superior efficiency; liquid cooled systems like Supermicro’s address high-performance AI thermal challenges |
| Immersion | $40K+ | >100kW | 1.05 | New build preferred | Ultimate thermal solution, typically requires purpose-built facilities |
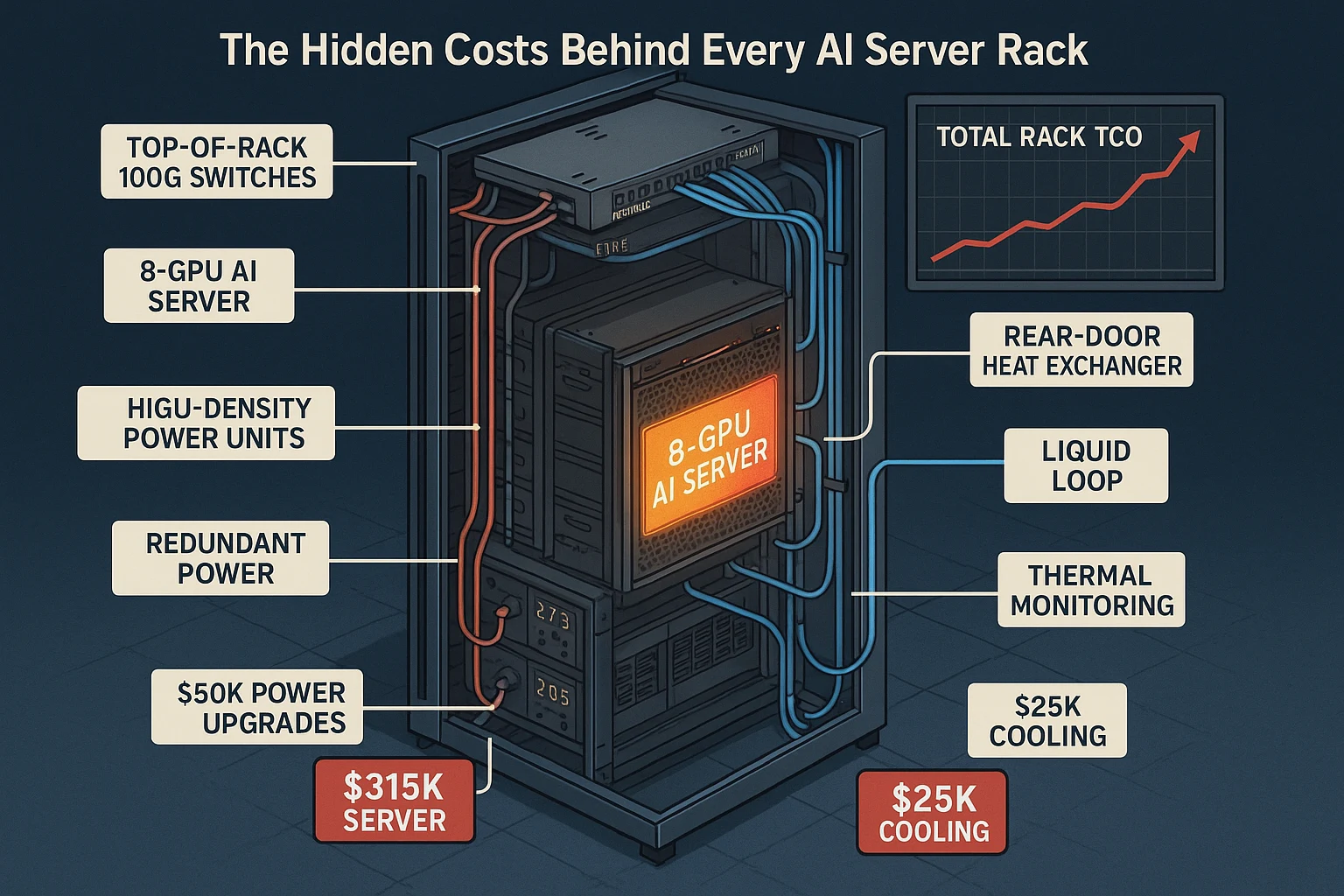
Accurately estimating AI server data center cost demands understanding the complete infrastructure stack, not just server hardware. Real-world deployments reveal shocking variations between entry-level and enterprise configurations:
| Component | Entry-Level Setup | Enterprise Setup | Notes |
|---|---|---|---|
| 8-GPU Server (e.g., H200 SXM) | $300,000 | $315,000 | HPE XD685 or Dell XE9680 config |
| Rack + PDU + Cabling | $4,000 | $10,000 | High-current PDUs for GPU racks |
| Liquid Cooling Loop | N/A | $25,000–$50,000 | Per rack for 50kW+, includes CDU, manifolds |
| Top-of-Rack Networking (100G) | $5,000 | $20,000 | Leaf switches, cabling, network fabric |
| Storage (NVMe-based, 1PB) | $20,000 | $50,000+ | Often missed in GPU-focused planning |
| Software Licenses (AI stack) | $5,000 | $50,000 | NVIDIA Enterprise AI, VMware, RedHat, etc. |
| Power Infrastructure Upgrades | $0–$10,000 | $50,000+ | Depends on facility capacity and redundancy needs |
| Integration & Installation | $3,000–$8,000 | $20,000+ | Structured cabling, test benching, configuration |
| Total (Per Rack Estimate) | ~$337K | ~$565K | Depends on density, cooling, and redundancy level |
Operating expenses for AI data centers extend far beyond basic electricity costs, devastating long-term AI server data center cost projections, with cooling efficiency playing a particularly crucial role in long-term profitability.
Energy Efficiency Breakdown
Energy efficiency differences between cooling technologies create substantial ongoing cost variations in AI server data center calculations. The following table illustrates the dramatic cost differences between cooling approaches:
| Server type | Cooling type | Annual Cooling Cost per Node | PUE Range | Annual Cost (50 Nodes) | Annual Savings vs Air-Cooled |
|---|---|---|---|---|---|
| H100 (air-cooled) | Traditional Air | $254 | 1.5 | $12,700 | – |
| H200 (liquid-cooled) | Direct liquid | $45 | 1.1–1.2 | $2,250 | $10,450 |
Key Takeaway: A facility running 50 AI nodes with liquid-cooled infrastructure slashes over $10,000 annually compared to air-cooled systems. This difference rapidly justifies higher initial cooling investments and dramatically reduces long-term AI server data center costs.
Maintenance contracts are a critical component of the AI server data center cost. Standard 3–5 year plans typically range from $15,000 to $40,000 per server, covering firmware, diagnostics, and parts replacement. Vendors like Supermicro offer flexible, OpEx-friendly options to help manage these expenses. However, most contracts exclude software reconfiguration, thermal tuning, and cooling system service-level agreements (SLAs), creating coverage gaps that can significantly impact operations.
Downtime costs often dwarf direct expenses. For production AI workloads, a high Mean Time To Resolution (MTTR) can trigger severe disruptions. To protect performance and avoid catastrophic risks, prioritize contracts that go beyond the basics and cover the whole operational stack.
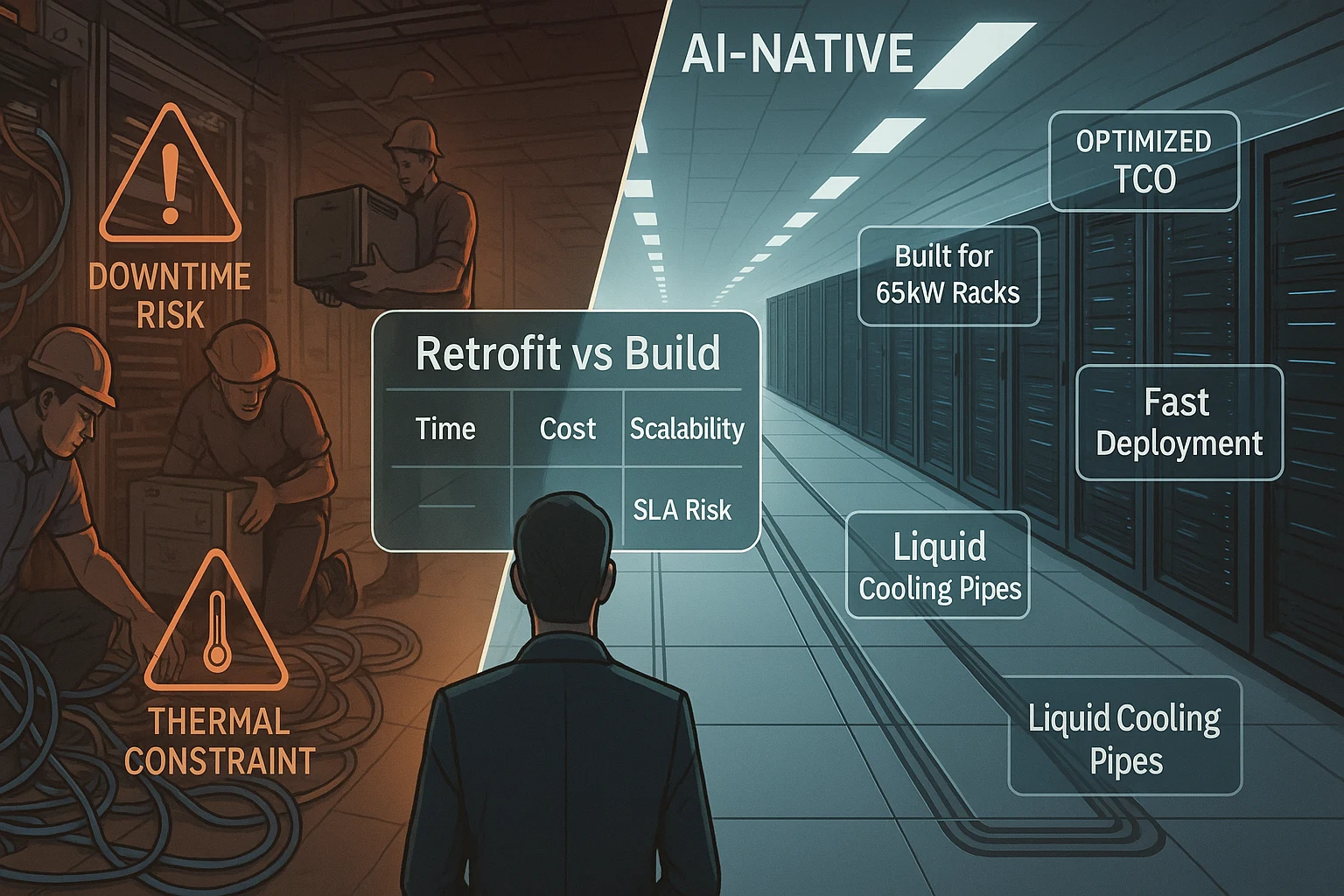
Organizations must weigh the critical tradeoff between retrofitting existing facilities and building AI-native data centers, each with distinct implications for the cost of AI server data centers.
Retrofitting allows for faster deployment and reuse of existing infrastructure; however, adapting sites for 50–80 kW racks with cooling solutions like CDUs and rear-door heat exchangers often results in extended downtime, punishing lead times for equipment, and crippling space limitations. Although upfront costs may seem lower, hidden expenses can skyrocket due to power and HVAC constraints, as well as complex integration work.
New builds support AI workloads by design, with three-phase power systems, built-in advanced cooling, and layout optimized for data flow and density. Although the initial investment is higher, total cost of ownership (TCO) analysis often favors this route. Case studies demonstrate over $150,000 in energy and SLA savings per rack over four years, thanks to superior cooling efficiency and reduced maintenance requirements.
Innovative deployment strategies can dramatically reduce AI server data center costs without compromising performance or reliability:
1. Staggered Deployment Mastery
Staggered Deployment Models eliminate massive upfront capital requirements by scaling infrastructure incrementally as workloads grow. This approach reduces financial risk while allowing organizations to incorporate lessons learned from initial deployments.
2. Hybrid Stack Intelligence
Hybrid Stack Planning maximizes resource allocation by deploying dedicated high-performance racks for inference workloads while sharing training resources across multiple applications. This strategy maximizes hardware utilization while controlling costs.
3. Workload-Optimized Hardware Selection
Server Selection Matching prevents over-provisioning by carefully aligning hardware capabilities with specific workload requirements. For example, Dell R760xa systems with L40S GPUs deliver excellent performance for inference applications at significantly lower costs than flagship H200 configurations.
4. Strategic Vendor Partnerships
Vendor Advisory Services help organizations navigate complex configuration decisions and avoid costly pitfalls. Specialized providers offer tailored SKU packages optimized for different rack densities and use cases.
5. Bundle Optimization
Marketplace Bundle Offers, combining servers, cooling, racks, and networking components, can provide cost advantages through volume purchasing and pre-validated compatibility.
A recent deployment illustrates the practical application of these cost optimization strategies and real-world AI server data center cost management. The client required infrastructure for large language model inference, running applications similar to Claude and LLaMA on Dell XE9680 platforms.
The solution combines AMD Instinct accelerators for training workloads with H200 GPUs for inference, implementing a three-tier cooling strategy that utilizes rear door heat exchangers and CDUs. This hybrid approach optimized performance for different workload types while effectively managing cooling costs.
The deployment achieved net total cost of ownership (TCO) savings of $280,000 over three years compared to traditional air-cooled alternatives, primarily through reduced energy consumption and improved reliability. The project demonstrated that thoughtful system design can deliver both performance and economic benefits while managing overall AI server data center costs.
AI infrastructure demands tight coordination across compute, storage, networking, and facilities—yet many organizations still underestimate non-hardware costs that make up half the total AI server data center cost. To avoid costly delays and performance bottlenecks, it’s essential to plan for the full stack from the start. Whether you’re building from scratch or scaling existing capacity, working with experienced partners can ensure your systems are aligned for efficiency, resilience, and growth.
The AI infrastructure landscape rewards preparation and punishes shortcuts. Organizations that invest in comprehensive planning and expert guidance achieve superior performance while maintaining financial discipline.
If you’re ready to optimize your AI deployment, now’s the time to invest in expert guidance that helps you get it right, from start to finish.
Ready to transform your AI infrastructure strategy? Request a custom AI data center cost analysis tailored to your specific requirements and discover how optimized infrastructure design delivers both breakthrough performance and compelling economics for your AI initiatives.






We are writing frequenly. Don’t miss that.

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now